| Delete Duplicate Data Using ROW_NUMBER() |
| Here is a way to delete duplicate data using the Oracle analytic function ROW_NUMBER() to delete duplicate data. The query column(s) that are duplicate have to be grouped in the PARTITION BY clause such that they create the row_number where the duplicate data will have row_number higher than one. The ORDER BY column creates the row_number order. |
| Create Duplicate Data |
| INSERT INTO Fact_Sales_Summary(month_id, sales_amount) |
| SELECT 201201, 34438 FROM DUAL; |
| INSERT INTO Fact_Sales_Summary(month_id, sales_amount) |
| SELECT 201301, 16389 FROM DUAL; |
| COMMIT; |
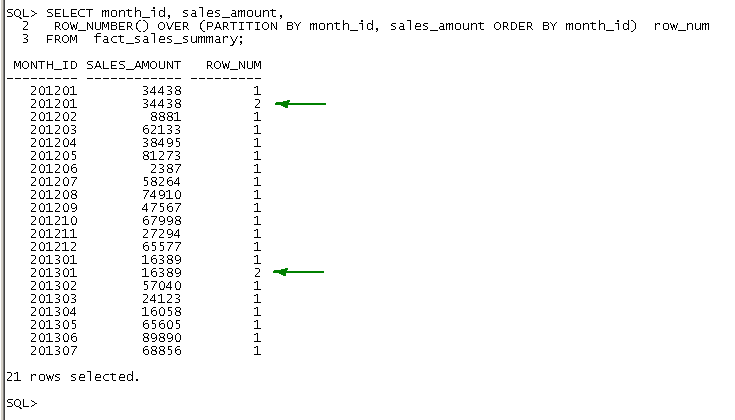
| Query To Review Duplicate Data |
| SELECT month_id, sales_amount, |
| ROW_NUMBER() OVER (PARTITION BY month_id, sales_amount ORDER BY month_id) row_num |
| FROM fact_sales_summary; |
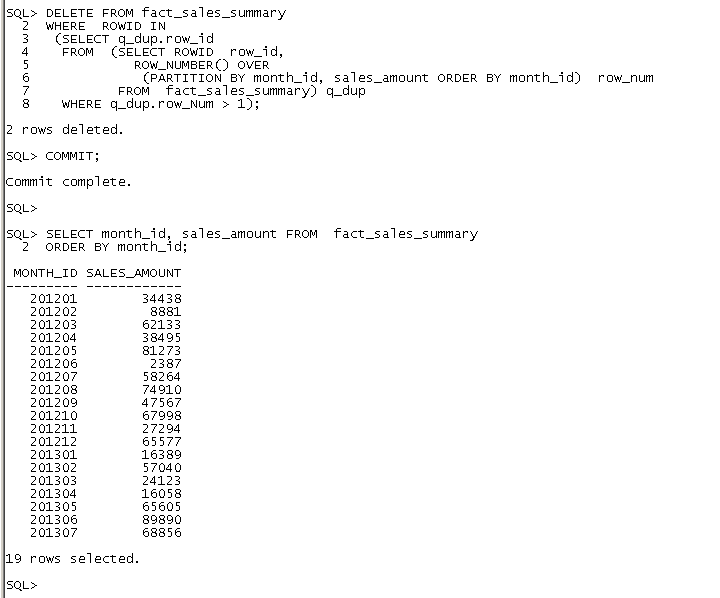
| Query To Delete Duplicate Data |
| DELETE FROM fact_sales_summary |
| WHERE ROWID IN |
| (SELECT q_dup.row_id |
| FROM (SELECT ROWID row_id, |
| ROW_NUMBER() OVER (PARTITION BY month_id, sales_amount ORDER BY month_id) row_num |
| FROM fact_sales_summary) q_dup |
| WHERE q_dup.row_Num > 1); |
| COMMIT; |
72701